
The Age of the Data Product
We are living through an information revolution. Like any economic revolution, it has had a transformative effect on society, academia, and business. The present revolution, driven as it is by networked communication systems and the Internet, is unique in that it has created a surplus of a valuable new material - data - and transformed us all into both consumers and producers. The sheer amount of data being generated is tremendous. Data increasingly affects every aspect of our lives, from the food we eat, to our social interactions, to the way we work and play. In turn, we have developed a reasonable expectation for products and services that are highly personalized and finely tuned to our bodies, our lives, and our businesses, creating a market for a new information technology - the data product.
The rapid and agile combination of surplus data sets with machine learning algorithms has changed the way that people interact with everyday things and each other because they so often lead to immediate and novel results. Indeed, the buzzword trend surrounding "big data" is related to the seemingly inexhaustible innovation that is available due to the large number of models and data sources.
Data products are created with data science workflows, specifically through the application of models, usually predictive or inferential, to a domain-specific data set. While the potential for innovation is great, the scientific or experimental mindset that is required to discover data sources and correctly model or mine patterns is not typically taught to programmers or analysts. Indeed, it is for this reason that it's cool to hire PhDs again - they have the required analytical and experimental training that, when coupled with programming foo, leads almost immediately to data science expertise. Of course, we can't all be PhDs. Instead, this article presents a pedagogical model for doing data science, and serves as a foundation for architecting applications that are, or can become, data products (minus the expensive and lengthy degree).
What is a Data Product?
The traditional answer to this question is usually "any application that combines data and algorithms." But to be frank, if you're writing software and you're not combining data with algorithms, then what are you doing? After all, data is the currency of programming! More specifically, we might say that a data product is the combination of data with statistical algorithms that are used for inference or prediction. Many data scientists are former statisticians, and statistical methodologies are central to data science.
Armed with this definition, you could cite Amazon recommendations as an example of a data product. They examine items you've purchased, and based on those interests, they make recommendations. In this case, order history data is combined with recommendation algorithms to make predictions about what you might purchase in the future. You might also cite Facebook's People You May Know because this product "shows you people based on mutual friends, work and education information ... [and] many other factors" - the combination of social network data with graph algorithms to infer members of communities.
These examples are certainly revolutionary in their own domains of retail and social networking, but they don't necessarily seem different from other web applications. Indeed, defining data products as simply the combination of data with statistical algorithms seems to limit data products to single software instances like a web application, which hardly seems a revolutionary economic force. Although we might point to Google or others as large scale economic forces, it is not simply the combination of web crawler and PageRank that has had a larger effect on the economy. Since we know what an important role search plays in economic activity, something must be missing from this first definition.
Mike Loukides argues that a data product is not simply another name for a "data-driven app." Although blogs, eCommerce platforms, and most web and mobile apps rely on a database and data services such as RESTful APIs, they are merely using data. That alone it is not a data product. Instead, in his excellent article, What is Data Science?, he defines a data product as follows:
A data application acquires its value from the data itself, and creates more data as a result. It's not just an application with data; it's a data product.
This is the revolution. A data product is an economic engine. It derives value from data and then produces more data, more value, in return. The data that it creates may fuel the generating product (we have finally achieved perpetual motion!) or it might lead to the creation of other data products that derive their value from that generated data. This is precisely what has led to the surplus of information and the resulting information revolution. More importantly, it is the generative effect that allows us to achieve better living through data, because more data products mean more data, which means even more data products, and so forth.
Armed with this more specific definition, we can go farther to describe data products as systems that are self adapting, learning, and broadly applicable. Under this definition, the Nest thermostat is a data product. It derives its value from sensor data and adapts, as a result, its own newly generated data. Autonomous vehicles such as those being produced by Stanford's Autonomous Driving Team also fall into this category. Their machine vision and pilot behavior simulation are the result of algorithms, so when the vehicle is in motion, it produces more data in the form of navigation and sensor data that can be used to improve their driving platform. The advent of the quantified self produced by Fitbit, Withings, and many others means that data affects human behavior; the smart grid means that data effects your utilities.
Data Products are self-adapting, broadly applicable economic engines that derive their value from data and generate more data by influencing human behavior or by making inferences or predictions upon new data.
Data products are not merely web applications and are rapidly becoming an essential component of almost every single domain of economic activity of the modern world. Because they are able to discover individual patterns in human activity, they drive decisions, whose resulting actions and influences are also recorded as new data.
Building Data Products
An oft-quoted tweet by Josh Wills informs us that a Data Scientist is:
Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.
Certainly this definition fits in well with the idea that a data product is simply the combination of data with statistical algorithms. Both software engineering and statistical knowledge are essential to data science. However, in an economy that demands products that derive their value from data and generate new data in return, we should say instead that as data scientists, it is our job to build data products.
Harlan Harris, provides more detail about the incarnation of data products: they are built at the intersection of data, domain knowledge, software engineering, and analytics. Because data products are systems, they require an engineering skill set, usually in software, in order to build them. They are powered by data, so having data is a necessary requirement. Domain knowledge and analytics are the tools used to build the data engine, usually via experimentation, hence the "science" part of data science.
Because of the experimental methodology required, most data scientists will point to this typical analytical workflow: ingestion → wrangling → modeling → reporting and visualization. Yet this so-called "data science pipeline" is completely human-powered, augmented by the use of scripting languages like R and Python. Human knowledge and analytical skill are required at every step of the pipeline, which is intended to produce unique, non-generalizable results. Although this pipeline is a good starting place as a statistical and analytical framework, it does not meet the requirements of building data products.
The Data Science Pipeline
The pipeline is a pedagogical model for teaching the workflow required for thorough statistical analyses of data, as shown in the figure below. In each phase, an analyst transforms an initial data set, augmenting or ingesting it from a variety of data sources, wrangling it into a normal form that can be computed upon, either with descriptive or inferential statistical methods, before producing a result via visualization or reporting mechanisms. These analytical procedures are usually designed to answer specific questions, or to investigate the relationship of data to some business practice for validation or decision-making.

This original workflow model has driven most early data science thought. Although it may come as a surprise, original discussions about the application of data science revolved around the creation of meaningful information visualization, primarily because this workflow is intended to produce something that allows humans to make decisions. By aggregating, describing, and modeling large data sets, humans are better able to make judgments based on patterns rather than individual data points. Data visualizations are nascent data products - they generate their value from data, then allow humans to take action based on what they learn, creating new data from those actions.
However, this model does not scale. The human-centric and one-way design of this workflow precludes the ability to efficiently design self-adapting systems that are able to learn. Machine learning algorithms have become widely available beyond academia, and fit the definition of data products very well. These types of algorithms derive their value from data as models are fit to existing data sets, then generate new data in return by making predictions about new observations.
In order to create machine learning systems, several things are required. First, an initial data set. If this initial data set is annotated with the "correct" answers, then our system will be supervised learning. If it is not, then we will be undertaking pattern analysis in an unsupervised form. Either way, some interactive work will be required to either annotate the initial dataset, or add labels to discovered patterns. After the initial dataset has been created, some model or algorithm is required to fit to our data. Models range from instance-based k-Nearest-Neighbors algorithms to recurrent neural networks. The time required to fit models is related to the complexity of computation and the size of the initial data set.
After a model has been fit to the initial data, it must be validated, that is, checked for its ability to accurately generalize to unseen input. A process of validation is to divide the shuffled training dataset into 12 parts. The model is fit on 10 of the parts, reinforced after training with one of the parts, and then tested on the last, unseen part. When this process is done 12 times, with each part omitted for validation once, the average of the accuracy gives a good sense of how the model will generalize (e.g. whether or not it overfits or has other biases). After validation, the model is trained on the entire training data set and stored so that it can be used to make predictions or estimations about new input data on demand. Finally, as new observations are made, the model should be adjusted through feedback in order to improve as new information becomes available.
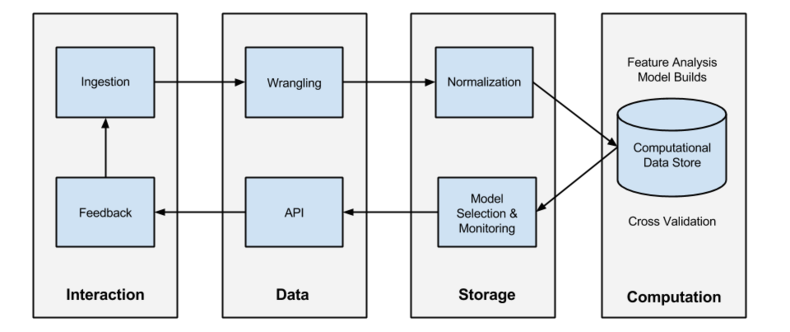
With the machine learning life cycle in mind, we can refactor the human-driven data science pipeline into an iterative model with four stages: interaction, data, storage, and computation, as shown in the figure above. The life cycle has two phases: the build phase, where models are trained and evaluated (the top section of the life cycle, ingestion through normalization), and an operational phase where models are used in practice (the bottom section of selection through feedback). Crucially, this pipeline builds feedback into the workflow, such that automatic systems can be built to self-adapt, and where the generation of new data is required.
- The interaction stage is where the model directly interacts with humans who either specify locations for data sources, annotate data (another form of ingestion), or consume the results of a model and provide feedback.
- The data stage is where transformations are applied to data to make it consumable, either by the model or through some other format.
- The storage stage handles the large quantities of data and parameters that are required for operation and provides a customization layer for individual users.
- Finally, the computation stage is the heavy lifting stage with the primary responsibility of training models and the management of a computational data store.
In the following sections, we will take a look at each phase and operation in the pipeline, and compare the data product pipeline to the data science pedagogical model.
The Training Phase
The training phase of the data product pipeline embeds the primary efforts of the original data science pipeline. Although the workflow can (and eventually should) be automated during this phase, often the training phase can be very hands-on and exploratory. In a typical architecture, the application can be built relatively early on, as the components of the operational phase can be seen as primarily engineering efforts. However, it is in the training phase that the primarily scientific efforts are undertaken.
Ingestion
Anand Rajaraman's semi-controversial statement that more data beats better algorithms has often been misused to imply that larger training datasets are required for more accurate machine learning models. This is partially true. Machine learning is essentially learning by example, and the greater the variety of examples, the more generalizable a model may become. However, Anand's post states that it wasn't simply more examples that provided better results, but rather more features, the inclusion of semi-related data for better decision-making on the part of the model.
Often, our core data products will be based on the investigation of a specific dataset, but the inclusion of other information is essential. Thanks to the Internet, there is a lot of data available to enhance our models. Web crawlers, APIs, sensors, and user-facing applications all provide essential data that needs to be collected and stored for use downstream in the data product pipeline. Often ingestion processes can be divided into two categories: ingestion of high volumes of data rarely or the continual ingestion of data that is constantly streaming into the system.
Ingested data is usually provided in a form that is usable to the provider of the data, and not immediately suited to the application of the consumer without some wrangling. After long experience, however, data scientists have learned never to throw out data that may become useful in the long run. Therefore ingested data is saved to an intermediary data store: write once, read many (WORM) storage. This storage is also occasionally called a "data lake."
Once data is collected, it has to be annotated in the case of supervised learning methods. The annotation process is interactive, where a human expert provides correct answers for some data set. The annotation process can also be seen as a data ingestion. Because of the requirements for annotation and WORM storage, often the ingestion component of a data product is a full application that includes web services and multi-process systems. Critically, this component should only fetch external data and store it. It should not make corrections or transform the data in any way. Any necessary transformations are left to the next stage.
Wrangling or Munging
Data, especially data created by humans, is never perfect. D.J. Patil stresses that 80% of the work of data science is cleaning bad data; the truism "garbage in, garbage out" certainly applies to predictive models. Occasionally, this is as simple as data type wrangling: data is usually ingested in a string format, and these formats must be parsed into their actual data types (dates, times, currencies, numbers, time zones, encoding, prices, or more complex structures like social networks, email, etc). Missing data must be either inferred (using a descriptive statistic like the mean, median, or mode) or simply dropped. Repeated data must be eliminated, and units need to be standardized (all temperatures to Celsius, for example).
Operations that are applied to data, such as filtering, aggregation, counting, normalization (as in database normalization), or denormalization (joining two tables), all ensure data is in a form it can be computed on. These processes are inherently destructive. The original data doesn't survive the wrangling process, which is why it's critical to make copies of the data.
The biggest challenge in wrangling is often dealing with multiple, similar data sources, all of which require special handling to get to some standardized form. A typical model is to create a template programming interface, where a base class includes several callable functions that expect output in the standard form. Subclasses handle specific cases, hoping to cover as much of the expected data as possible. Finally, leaf nodes handle individual data sources. With this construct in place, a simple mapping of source to template creates a robust and flexible data wrangling system, though there is no avoiding per-source wrangling efforts.
The last piece to consider in the wrangling phase, and one that extends to the normalization phase, is initial feature extraction. Once all data is more or less in a similar format, features must be generated or extracted into a usable representation. For example, textual data requires segmentation (splitting into sentences), tokenization (splitting into word forms), part of speech tagging, lexical disambiguation, feature space reduction (lemmatization or stemming), or even parsing for structural analyses. Sound files need to be transcribed, video files need to be marked, etc. Graphs need to be simplified through entity resolution. Statistical processes are often used to perform these extractions, and the wrangling phase may include smaller, internal data products that follow a similar life cycle.
Normalization
In order to provide transactional or aggregate operations on many instances of data used in statistical processes, a data warehouse is required. This is especially true when the volume of data often cannot simply be kept in memory, but requires some data management system. Extract, transform, and load (ETL) methodologies operationalize wrangling methods to move data to operational storage locations. In order to train a model, many examples or instances are required, but those instances need to be in a normal form since the instance is usually described by a complex data type.
Normalization in this context usually refers to relational database normalization, but similar techniques are also essential to NoSQL data warehouses. One efficient way to implement machine learning algorithms is to use graph algorithms, since graph data structures provide inherent efficiencies for iterative data processing. NoSQL graph databases, like Neo4j, require data to be stored in the property graph format. Graph normalization, therefore, is the modeling and extraction of nodes and relationships, and both vertices and edges require relevant properties added to instances. Columnar or document data stores also have their own challenges for data storage that need to be tackled in this phase.
Once data is in a normal form it is stored in a computational data store - a repository of instance data that can be explored using traditional analytical techniques. It is very popular to hook Tableau up to PostgreSQL to do data explorations, or to use SQL or Cypher to perform queries or analyses to generate hypotheses. The computational data store is the central component for all operations surrounding the data product.
Computation and Modeling
Once data has been ingested, the computational data store is used to define and build predictive models. This is the "sexy" part of data analytics and data science, and most data science literature relates to these processes. In order to build predictive models, three primary activities are required:
- Feature analysis - the identification and computation of informative aspects of data that will lead to prediction.
- Training - the fitting of data to a model.
- Validation - testing how good a model is able to generalize to unseen input.
Feature analysis is used to identify key data points and to develop dimensions upon which to perform predictions and analyses. The work of feature analysis often leads to more feature extraction, which filters back to the wrangling and normalization stages. Models are usually created on both a human hypothesis basis, as well as searching a large data space. Because of this, feature analysis is usually an iterative process that requires a clean data store and significant computational time.
Models themselves also must be computed, a process called training or fitting. Training involves the optimization of a cost curve to select the model parameters for a specific space. Optimization is iterative, and computationally time consuming. Descriptive statistics, sampling, aggregations, and analysis of variance all assist in model optimization, but these computations can be time consuming. In order to reduce computational time, associated computations such as indices, relations, internal classifiers or clustering may be used to make downstream calculations more efficient. Parameterizing the model itself might also involve brute force grid searches.
In order to make this phase efficient, a data product normally employs a strategy of continuous builds: a process whereby models are constantly computed upon on a regular basis (e.g. nightly or weekly). For some very computationally intensive models like recurrent neural networks, this process might be overlapping, for others like SVMs, a variety of models with different parameterizations (different kernel functions, alphas, gammas, etc.) might be built in parallel. In order to determine the efficacy of a variety of models, cross-validation is used and the model with the highest score (accuracy, precision, recall, F1, R-squared, etc.) is then saved to disk to be used during the operational phase.
Cross validation is used to ensure that a model is not biased through overfitting such that it can generalize well to unseen data. In the 12-part cross validation approach mentioned previously, the final test of goodness is the average of some statistical score across all twelve parts. This score is saved, along with the final model, to be used in production.
The Operational Phase
The operational phase extends the original data science pipeline to create a workflow that is designed for the production deployment of statistical models in data products. During this phase, models that are stored in the computational data store are used to make predictions and generate new data in real time in customer facing applications. This phase can power visualizations and reporting tools that were the traditional work products of the original data science pipeline, but also attempts to incorporate feedback and interaction into a data lifecycle that will continuously grow the data product.
Model Selection & Monitoring
Usually a data product is not a single model, but rather an ensemble of models that are used for a variety of tasks during interaction with the user. Models are generated on a routine basis, while data is continually ingested as more feedback is collected. Models can also be generated on different samples of data, producing a variety of accuracy scores. As the computational phase creates and stores multiple models on disk, a selection process is required to use the model in routine operation. This can be as simple as choosing the latest model or the one with the highest goodness-of-fit score (lowest mean square error, highest coefficient of determination, highest accuracy, best F1 score, etc). More complex methods use A/B testing or multi-armed bandits to select models and optimize "exploration vs. exploitation" in real time.
Alternatively, the model selection phase might not be to operationalize some predictive model into the application, but rather to pre-compute results for immediate reuse. This is very common for recommendation systems where, instead of computing recommendations for a particular user when a user adds a product to a cart, recommendations are computed on a per-user or per-item basis and displayed immediately. Usually pre-computation is an offline process where an entire data store is updated or replaced by the new results and then swapped in for immediate use in the system.
Whichever workflow is chosen for an application, consideration must be paid to the storage components of the interactive system. Because there are multiple models and multiple options for deploying models, this stage is usually where post-evaluation occurs on models, experimenting on their efficacy "in the wild." Monitoring the behavior of different types of predictive models ensures that the entire system continues to perform well over time. Model build phases can be adapted as a result of such monitoring. For example, a model can be made to "forget" old training data that may no longer be relevant, thereby improving its utility. In order to implement selection and monitoring phases, close interaction with both the previous computational phase as well as the next phase, the API, is required.
API
Data products are implemented as software products in a variety of domains - not just on the web, but also in physical products. No matter their implementation, some interaction with the predictive or inferential capabilities of the model is required: whether it is interacting with a model that is loaded into memory to compute on demand or whether it is looking up the pre-computed predictions in a database. The glue between an end user and the model is the application programming interface, or API.
When most people think of APIs, they think of RESTful web interfaces, which are an extremely good examples of how to employ or deploy data products. A RESTful API accepts an HTTP request and returns a structured response, usually via some serialization mechanism like JSON or XML. The simplest API for a data product is a GET request with some feature vector, whose response is a prediction or estimation, and a POST request with some indication of whether or not the prediction was accurate. This simple architecture can be used in a variety of applications, or as connective glue between the various components of larger applications. It behooves data scientists to learn how to create simple APIs like this for effective deployment of their models!
A RESTful API isn't the only type of interface for a data product. A CSV dump of data, streaming data on demand, or micro-services can all power a suite of tools and are all data products. It is very popular to create simple HTML5 applications using D3 and static JSON data for visualizations and mash-ups. However the API is implemented, it serves as the connective tissue between the back-end data and the user, and is a vital component of building data products.
Feedback
Users interact directly with an API or with an application that is powered by an API (e.g. a mobile app, a web site, a thermostat, a report, or even a visualization). It is through the interaction of users with the system that new data is generated: either as the user makes more requests or gives more information (e.g. an effective search tool will get more searches, which power more effective search) or as the user validates the response of the system (by purchasing a recommended product or by upvoting, tagging, or any other interaction). Although often overlooked, having a system that accepts feedback is essential to creating a self-adapting system and to take advantage of the economic gains of data products which generate more data.
Humans recognize patterns effectively and on a per-instance basis can bring a wide variety of experience and information to bear on a problem solving task. For this reason, human feedback is critical for active learning - machine learning where the system rebuilds models by detecting error. The action/interaction cycle is part of what drives the engine of data generation, building more value as humans react to or utilize information from different systems. It is this final piece of the data product pipeline that makes this workflow a life cycle, rather than simply a static pipeline.
Conclusion
The conversation regarding what data science is has changed over the course of the past decade, moving from the purely analytical towards more visualization-related methods, and now to the creation of data products. Data products are economic engines that derive their value from data, are self-adapting, learning, and broadly applicable, and generate new data in return. Data products have engaged a new information economy revolution that has changed the way that small business, technology startups, larger organizations, and government view their data.
In this post, we've described a revision to the original pedagogical model of the data science pipeline, and proposed a data product pipeline. The data product pipeline is iterative, with two phases: the building phase and the operational phase, and four stages: interaction, data, storage, and computation. It serves as an architecture for performing large scale data analyses in a methodical fashion that preserves experimentation and human interaction with data products, but also enables parts of the process to become automated as larger applications are built around them. We hope that this pipeline can be used as a general framework for understanding the data product lifecycle, but also as a stepping stone so that more innovative projects may be explored.
As always, please follow @DistrictDataLab on Twitter and if you liked the post, subscribe to this blog by clicking the Subscribe button below.
District Data Labs provides data science consulting and corporate training services. We work with companies and teams of all sizes, helping them make their operations more data-driven and enhancing the analytical abilities of their employees. Interested in working with us? Let us know!
