
This is the second post in our Data Exploration with Python series. Before reading this post, make sure to check out Data Exploration with Python, Part 1!
Mise en place (noun): In a professional kitchen, the disciplined organization and preparation of equipment and food before service begins.
When performing exploratory data analysis (EDA), it is important to not only prepare yourself (the analyst) but to prepare your data as well. As we discussed in the previous post, a small amount of preparation will often save you a significant amount of time later on. So let's review where we should be at this point and then continue our exploration process with data preparation.
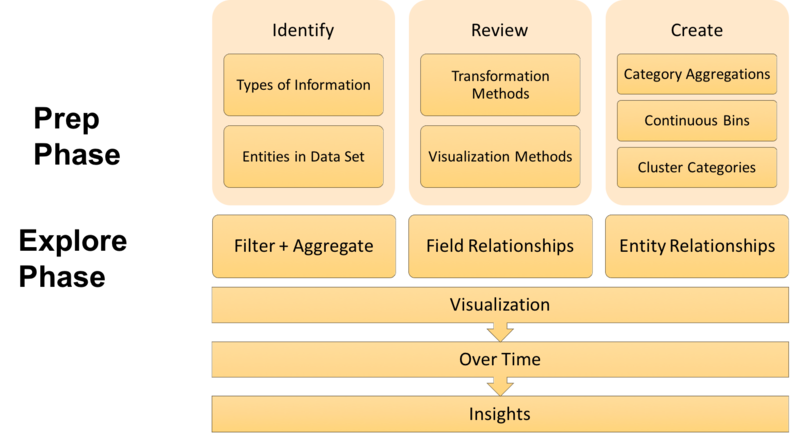
In Part 1 of this series, we were introduced to the data exploration framework we will be using. As a reminder, here is what that framework looks like.
We also introduced the example data set we are going to be using to illustrate the different phases and stages of the framework. Here is what that looks like.

We then familiarized ourselves with our data set by identifying the types of information and entities encoded within it. We also reviewed several data transformation and visualization methods that we will use later to explore and analyze it. Now we are at the last stage of the framework's Prep Phase, the Create stage, where our goal will be to create additional categorical fields that will make our data easier to explore and allow us to view it from new perspectives.
Renaming Columns to be More Intuitive
Before we dive in and start creating categories, however, we have an opportunity to improve our categorization efforts by examining the columns in our data and making sure their labels intuitively convey what they represent. Just as with the other aspects of preparation, changing them now will save us from having to remember what displ or co2TailpipeGpm mean when they show up on a chart later. In my experience, these small, detail-oriented enhancements to the beginning of your process usually compound and preserve cognitive cycles that you can later apply to extracting insights.
We can use the code below to rename the columns in our vehicles data frame.
vehicles.columns = ['Make','Model','Year','Engine Displacement','Cylinders',
'Transmission','Drivetrain','Vehicle Class','Fuel Type',
'Fuel Barrels/Year','City MPG','Highway MPG','Combined MPG',
'CO2 Emission Grams/Mile','Fuel Cost/Year']
Thinking About Categorization
Now that we have changed our column names to be more intuitive, let's take a moment to think about what categorization is and examine the categories that currently exist in our data set. At the most basic level, categorization is just a way that humans structure information — how we hierarchically create order out of complexity. Categories are formed based on attributes that entities have in common, and they present us with different perspectives from which we can view and think about our data.
Our primary objective in this stage is to create additional categories that will help us further organize our data. This will prove beneficial not only for the exploratory analysis we will conduct but also for any supervised machine learning or modeling that may happen further down the data science pipeline. Seasoned data scientists know that the better your data is organized, the better downstream analyses you will be able to perform and the more informative features you will have to feed into your machine learning models.
In this stage of the framework, we are going to create additional categories in 3 distinct ways:
- Category Aggregations
- Binning Continuous Variables
- Clustering
Now that we have a better idea of what we are doing and why, let's get started.
Aggregating to Higher-Level Categories
The first way we are going to create additional categories is by identifying opportunities to create higher-level categories out of the variables we already have in our data set. In order to do this, we need to get a sense of what categories currently exist in the data. We can do this by iterating through our columns and printing out the name, the number of unique values, and the data type for each.
def unique_col_values(df):
for column in df:
print("{} | {} | {}".format(
df[column].name, len(df[column].unique()), df[column].dtype
))
unique_col_values(vehicles)
Make | 126 | object
Model | 3491 | object
Year | 33 | int64
Engine Displacement | 65 | float64
Cylinders | 9 | float64
Transmission | 43 | object
Drivetrain | 7 | object
Vehicle Class | 34 | object
Fuel Type | 13 | object
Fuel Barrels/Year | 116 | float64
City MPG | 48 | int64
Highway MPG | 49 | int64
Combined MPG | 45 | int64
CO2 Emission Grams/Mile | 550 | float64
Fuel Cost/Year | 58 | int64
From looking at the output, it is clear that we have some numeric columns (int64 and float64) and some categorical columns (object). For now, let's focus on the six categorical columns in our data set.
- Make: 126 unique values
- Model: 3,491 unique values
- Transmission: 43 unique values
- Drivetrain: 7 unique values
- Vehicle Class: 34 unique values
- Fuel Type: 13 unique values
When aggregating and summarizing data, having too many categories can be problematic. The average human is said to have the ability to hold 7 objects at a time in their short-term working memory. Accordingly, I have noticed that once you exceed 8-10 discrete values in a category, it becomes increasingly difficult to get a holistic picture of how the entire data set is divided up.
What we want to do is examine the values in each of our categorical variables to determine where opportunities exist to aggregate them into higher-level categories. The way this is typically done is by using a combination of clues from the current categories and any domain knowledge you may have (or be able to acquire).
For example, imagine aggregating by Transmission, which has 43 discrete values in our data set. It is going to be difficult to derive insights due to the fact that any aggregated metrics are going to be distributed across more categories than you can hold in short-term memory. However, if we examine the different transmission categories with the goal of finding common features that we can group on, we would find that all 43 values fall into one of two transmission types, Automatic or Manual.

Let's create a new Transmission Type column in our data frame and, with the help of the loc method in pandas, assign it a value of Automatic where the first character of Transmission is the letter A and a value of Manual where the first character is the letter M.
AUTOMATIC = "Automatic"
MANUAL = "Manual"
vehicles.loc[vehicles['Transmission'].str.startswith('A'),
'Transmission Type'] = AUTOMATIC
vehicles.loc[vehicles['Transmission'].str.startswith('M'),
'Transmission Type'] = MANUAL
We can apply the same logic to the Vehicle Class field. We originally have 34 vehicle classes, but we can distill those down into 8 vehicle categories, which are much easier to remember.

small = ['Compact Cars','Subcompact Cars','Two Seaters','Minicompact Cars']
midsize = ['Midsize Cars']
large = ['Large Cars']
vehicles.loc[vehicles['Vehicle Class'].isin(small),
'Vehicle Category'] = 'Small Cars'
vehicles.loc[vehicles['Vehicle Class'].isin(midsize),
'Vehicle Category'] = 'Midsize Cars'
vehicles.loc[vehicles['Vehicle Class'].isin(large),
'Vehicle Category'] = 'Large Cars'
vehicles.loc[vehicles['Vehicle Class'].str.contains('Station'),
'Vehicle Category'] = 'Station Wagons'
vehicles.loc[vehicles['Vehicle Class'].str.contains('Truck'),
'Vehicle Category'] = 'Pickup Trucks'
vehicles.loc[vehicles['Vehicle Class'].str.contains('Special Purpose'),
'Vehicle Category'] = 'Special Purpose'
vehicles.loc[vehicles['Vehicle Class'].str.contains('Sport Utility'),
'Vehicle Category'] = 'Sport Utility'
vehicles.loc[(vehicles['Vehicle Class'].str.lower().str.contains('van')),
'Vehicle Category'] = 'Vans & Minivans'
Next, let's look at the Make and Model fields, which have 126 and 3,491 unique values respectively. While I can't think of a way to get either of those down to 8-10 categories, we can create another potentially informative field by concatenating Make and the first word of the Model field together into a new Model Type field. This would allow us to, for example, categorize all Chevrolet Suburban C1500 2WD vehicles and all Chevrolet Suburban K1500 4WD vehicles as simply Chevrolet Suburbans.
vehicles['Model Type'] = (vehicles['Make'] + " " +
vehicles['Model'].str.split().str.get(0))
Finally, let's look at the Fuel Type field, which has 13 unique values. On the surface, that doesn't seem too bad, but upon further inspection, you'll notice some complexity embedded in the categories that could probably be organized more intuitively.
vehicles['Fuel Type'].unique()
array(['Regular', 'Premium', 'Diesel', 'Premium and Electricity',
'Premium or E85', 'Premium Gas or Electricity', 'Gasoline or E85',
'Gasoline or natural gas', 'CNG', 'Regular Gas or Electricity',
'Midgrade', 'Regular Gas and Electricity', 'Gasoline or propane'],
dtype=object)
This is interesting and a little tricky because there are some categories that contain a single fuel type and others that contain multiple fuel types. In order to organize this better, we will create two sets of categories from these fuel types. The first will be a set of columns that will be able to represent the different combinations, while still preserving the individual fuel types.
vehicles['Gas'] = 0
vehicles['Ethanol'] = 0
vehicles['Electric'] = 0
vehicles['Propane'] = 0
vehicles['Natural Gas'] = 0
vehicles.loc[vehicles['Fuel Type'].str.contains(
'Regular|Gasoline|Midgrade|Premium|Diesel'),'Gas'] = 1
vehicles.loc[vehicles['Fuel Type'].str.contains('E85'),'Ethanol'] = 1
vehicles.loc[vehicles['Fuel Type'].str.contains('Electricity'),'Electric'] = 1
vehicles.loc[vehicles['Fuel Type'].str.contains('propane'),'Propane'] = 1
vehicles.loc[vehicles['Fuel Type'].str.contains('natural|CNG'),'Natural Gas'] = 1
As it turns out, 99% of the vehicles in our database have gas as a fuel type, either by itself or combined with another fuel type. Since that is the case, let's create a second set of categories - specifically, a new Gas Type field that extracts the type of gas (Regular, Midgrade, Premium, Diesel, or Natural) each vehicle accepts.
vehicles.loc[vehicles['Fuel Type'].str.contains(
'Regular|Gasoline'),'Gas Type'] = 'Regular'
vehicles.loc[vehicles['Fuel Type'] == 'Midgrade',
'Gas Type'] = 'Midgrade'
vehicles.loc[vehicles['Fuel Type'].str.contains('Premium'),
'Gas Type'] = 'Premium'
vehicles.loc[vehicles['Fuel Type'] == 'Diesel',
'Gas Type'] = 'Diesel'
vehicles.loc[vehicles['Fuel Type'].str.contains('natural|CNG'),
'Gas Type'] = 'Natural'
An important thing to note about what we have done with all of the categorical fields in this section is that, while we created new categories, we did not overwrite the original ones. We created additional fields that will allow us to view the information contained within the data set at different (often higher) levels. If you need to drill down to the more granular original categories, you can always do that. However, now we have a choice whereas before we performed these category aggregations, we did not.
Creating Categories from Continuous Variables
The next way we can create additional categories in our data is by binning some of our continuous variables - breaking them up into different categories based on a threshold or distribution. There are multiple ways you can do this, but I like to use quintiles because it gives me one middle category, two categories outside of that which are moderately higher and lower, and then two extreme categories at the ends. I find that this is a very intuitive way to break things up and provides some consistency across categories. In our data set, I've identified 4 fields that we can bin this way.

Binning essentially looks at how the data is distributed, creates the necessary number of bins by splitting up the range of values (either equally or based on explicit boundaries), and then categorizes records into the appropriate bin that their continuous value falls into. Pandas has a qcut method that makes binning extremely easy, so let's use that to create our quintiles for each of the continuous variables we identified.
efficiency_categories = ['Very Low Efficiency', 'Low Efficiency',
'Moderate Efficiency','High Efficiency',
'Very High Efficiency']
vehicles['Fuel Efficiency'] = pd.qcut(vehicles['Combined MPG'],
5, efficiency_categories)
engine_categories = ['Very Small Engine', 'Small Engine','Moderate Engine',
'Large Engine', 'Very Large Engine']
vehicles['Engine Size'] = pd.qcut(vehicles['Engine Displacement'],
5, engine_categories)
emission_categories = ['Very Low Emissions', 'Low Emissions',
'Moderate Emissions','High Emissions',
'Very High Emissions']
vehicles['Emissions'] = pd.qcut(vehicles['CO2 Emission Grams/Mile'],
5, emission_categories)
fuelcost_categories = ['Very Low Fuel Cost', 'Low Fuel Cost',
'Moderate Fuel Cost','High Fuel Cost',
'Very High Fuel Cost']
vehicles['Fuel Cost'] = pd.qcut(vehicles['Fuel Cost/Year'],
5, fuelcost_categories)
Clustering to Create Additional Categories
The final way we are going to prepare our data is by clustering to create additional categories. There are a few reasons why I like to use clustering for this. First, it takes multiple fields into consideration together at the same time, whereas the other categorization methods only consider one field at a time. This will allow you to categorize together entities that are similar across a variety of attributes, but might not be close enough in each individual attribute to get grouped together.
Clustering also creates new categories for you automatically, which takes much less time than having to comb through the data yourself identifying patterns across attributes that you can form categories on. It will automatically group similar items together for you.
The third reason I like to use clustering is because it will sometimes group things in ways that you, as a human, may not have thought of. I'm a big fan of humans and machines working together to optimize analytical processes, and this is a good example of value that machines bring to the table that can be helpful to humans. I'll write more about my thoughts on that in future posts, but for now, let's move on to clustering our data.
The first thing we are going to do is isolate the columns we want to use for clustering. These are going to be columns with numeric values, as the clustering algorithm will need to compute distances in order to group similar vehicles together.
cluster_columns = ['Engine Displacement','Cylinders','Fuel Barrels/Year',
'City MPG','Highway MPG','Combined MPG',
'CO2 Emission Grams/Mile', 'Fuel Cost/Year']
Next, we want to scale the features we are going to cluster on. There are a variety of ways to normalize and scale variables, but I'm going to keep things relatively simple and just use Scikit-Learn's MaxAbsScaler, which will divide each value by the max absolute value for that feature. This will preserve the distributions in the data and convert the values in each field to a number between 0 and 1 (technically -1 and 1, but we don't have any negatives).
from sklearn import preprocessing
scaler = preprocessing.MaxAbsScaler()
vehicle_clusters = scaler.fit_transform(vehicles[cluster_columns])
vehicle_clusters = pd.DataFrame(vehicle_clusters, columns=cluster_columns)
Now that our features are scaled, let's write a couple of functions. The first function we are going to write is a kmeans_cluster function that will k-means cluster a given data frame into a specified number of clusters. It will then return a copy of the original data frame with those clusters appended in a column named Cluster.
from sklearn.cluster import KMeans
def kmeans_cluster(df, n_clusters=2):
model = KMeans(n_clusters=n_clusters, random_state=1)
clusters = model.fit_predict(df)
cluster_results = df.copy()
cluster_results['Cluster'] = clusters
return cluster_results
Our second function, called summarize_clustering is going to count the number of vehicles that fall into each cluster and calculate the cluster means for each feature. It is going to merge the counts and means into a single data frame and then return that summary to us.
def summarize_clustering(results):
cluster_size = results.groupby(['Cluster']).size().reset_index()
cluster_size.columns = ['Cluster', 'Count']
cluster_means = results.groupby(['Cluster'], as_index=False).mean()
cluster_summary = pd.merge(cluster_size, cluster_means, on='Cluster')
return cluster_summary
We now have functions for what we need to do, so the next step is to actually cluster our data. But wait, our kmeans_cluster function is supposed to accept a number of clusters. How do we determine how many clusters we want?
There are a number of approaches for figuring this out, but for the sake of simplicity, we are just going to plug in a couple of numbers and visualize the results to arrive at a good enough estimate. Remember earlier in this post where we were trying to aggregate our categorical variables to less than 8-10 discrete values? We are going to apply the same logic here. Let's start out with 8 clusters and see what kind of results we get.
cluster_results = kmeans_cluster(vehicle_clusters, 8)
cluster_summary = summarize_clustering(cluster_results)
After running the couple of lines of code above, your cluster_summary should look similar to the following.

By looking at the Count column, you can tell that there are some clusters that have significantly more records in them (ex. Cluster 7) and others that have significantly fewer (ex. Cluster 3). Other than that, though, it is difficult to notice anything informative about the summary. I don't know about you, but to me, the rest of the summary just looks like a bunch of decimals in a table.
This is a prime opportunity to use a visualization to discover insights faster. With just a couple import statements and a single line of code, we can light this summary up in a heatmap so that we can see the contrast between all those decimals and between the different clusters.
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(cluster_summary[cluster_columns].transpose(), annot=True)

In this heatmap, the rows represent the features and the columns represent the clusters, so we can compare how similar or differently columns look to each other. Our goal for clustering these features is to ultimately create meaningful categories out of the clusters, so we want to get to the point where we can clearly distinguish one from the others. This heatmap allows us to do this quickly and visually.
With this goal in mind, it is apparent that we probably have too many clusters because:
- Clusters 3, 4, and 7 look pretty similar
- Clusters 2 and 5 look similar as well
- Clusters 0 and 6 are also a little close for comfort
From the way our heatmap currently looks, I'm willing to bet that we can cut the number of clusters in half and get clearer boundaries. Let's re-run the clustering, summary, and heatmap code for 4 clusters and see what kind of results we get.
cluster_results = kmeans_cluster(vehicle_clusters, 4)
cluster_summary = summarize_clustering(cluster_results)
sns.heatmap(cluster_summary[cluster_columns].transpose(), annot=True)

These clusters look more distinct, don't they? Clusters 1 and 3 look like they are polar opposites of each other, cluster 0 looks like it’s pretty well balanced across all the features, and cluster 2 looks like it’s about half-way between Cluster 0 and Cluster 1.
We now have a good number of clusters, but we still have a problem. It is difficult to remember what clusters 0, 1, 2, and 3 mean, so as a next step, I like to assign descriptive names to the clusters based on their properties. In order to do this, we need to look at the levels of each feature for each cluster and come up with intuitive natural language descriptions for them. You can have some fun and can get as creative as you want here, but just keep in mind that the objective is for you to be able to remember the characteristics of whatever label you assign to the clusters.
- Cluster 1 vehicles seem to have large engines that consume a lot of fuel, process it inefficiently, produce a lot of emissions, and cost a lot to fill up. I'm going to label them Large Inefficient.
- Cluster 3 vehicles have small, fuel efficient engines that don't produce a lot of emissions and are relatively inexpensive to fill up. I'm going to label them Small Very Efficient.
- Cluster 0 vehicles are fairly balanced across every category, so I'm going to label them Midsized Balanced.
- Cluster 2 vehicles have large engines but are more moderately efficient than the vehicles in Cluster 1, so I'm going to label them Large Moderately Efficient.
Now that we have come up with these descriptive names for our clusters, let's add a Cluster Name column to our cluster_results data frame, and then copy the cluster names over to our original vehicles data frame.
cluster_results['Cluster Name'] = ''
cluster_results['Cluster Name'][cluster_results['Cluster']==0] = 'Midsized Balanced'
cluster_results['Cluster Name'][cluster_results['Cluster']==1] = 'Large Inefficient'
cluster_results['Cluster Name'][cluster_results['Cluster']==2] = 'Large Moderately Efficient'
cluster_results['Cluster Name'][cluster_results['Cluster']==3] = 'Small Very Efficient'
vehicles = vehicles.reset_index().drop('index', axis=1)
vehicles['Cluster Name'] = cluster_results['Cluster Name']
Conclusion
In this post, we examined several ways to prepare a data set for exploratory analysis. First, we looked at the categorical variables we had and attempted to find opportunities to roll them up into higher-level categories. After that, we converted some of our continuous variables into categorical ones by binning them into quintiles based on how relatively high or low their values were. Finally, we used clustering to efficiently create categories that automatically take multiple fields into consideration. The result of all this preparation is that we now have several columns containing meaningful categories that will provide different perspectives of our data and allow us to acquire as many insights as possible.
Now that we have these meaningful categories, our data set is in really good shape, which means that we can move on to the next phase of our data exploration framework. In the next post, we will cover the first two stages of the Explore Phase and demonstrate various ways to visually aggregate, pivot, and identify relationships between fields in our data. Make sure to subscribe to the DDL blog so that you get notified when we publish it!
District Data Labs provides data science consulting and corporate training services. We work with companies and teams of all sizes, helping them make their operations more data-driven and enhancing the analytical abilities of their employees. Interested in working with us? Let us know!
Tony Ojeda - Founder of District Data Labs - Email
